影刀RPA新手教程:零基础入门完全指南——从下载安装到独立开发你的第一个自动化流程

影刀RPA新手教程零基础入门完全指南——从下载安装到独立开发你的第一个自动化流程我第一次接触影刀的时候完全不知道RPA是什么更别提什么元素捕获、XPath这些词了。折腾了两个礼拜踩了无数坑才把第一个能跑起来的流程写出来。这篇文章就是我把自己走过的路重新捋一遍让零基础的你不用再像我一样摸黑。影刀RPA说白了就是一个帮你自动操作电脑的软件。你平时在电脑上做的重复操作——打开网页、复制粘贴、填写表格、点击按钮——影刀都能替你干。你只需要告诉它点哪里、填什么它就会照做。听起来简单但实际操作中有太多细节需要注意下面我就从头讲起。一、下载安装影刀客户端去影刀官网下载安装包Windows系统直接双击安装就行。安装完之后用手机号注册一个账号登录进来你会看到一个编辑器界面左边是指令面板中间是流程编排区右边是元素库和变量区。我第一次装的时候遇到一个问题装完打不开编辑器。排查了一下午才发现是360桌面整理助手在捣鬼——影刀的元素捕获机制和这类桌面管理工具冲突。如果你也遇到打不开或者捕获不了元素的情况先把360桌面整理、腾讯桌面整理、动态壁纸这些软件关掉再试。实在不行影刀还有个深度模式捕获在捕获按钮旁边可以切换专门对付这些特殊情况。二、元素定位告诉影刀点哪里元素定位是影刀最核心的能力。你得让影刀知道它要操作的具体是屏幕上的哪个东西。影刀提供了三种主要定位方式元素捕获、XPath和CSS选择器。元素捕获是最直观的。点击捕获新元素鼠标移到你想操作的按钮或文本上影刀会自动识别并高亮显示点一下就捕获完成了。捕获后可以在元素库里看到这个元素的特征信息。但元素捕获不是万能的。有些网页元素长得很像比如列表里每一行你需要捕获相似元素组——先捕获一个再点捕获相似元素选另一个同类元素影刀就能识别出这一整组。这个在做小红书笔记采集的时候特别常用因为搜索结果页的每条笔记结构都是一样的。XPath是另一种强大的定位方式。它通过路径表达式在网页的HTML结构中找到目标元素。//*[idsu]这行XPath的意思是找页面中id为su的任意元素。在百度搜索页面上这就是那个百度一下按钮。影刀里用XPath定位既可以在获取元素对象(web)指令里选择XPath定位方式也可以在Python代码里直接调用fromxbotimportwebdefmain(args):browserweb.get_active()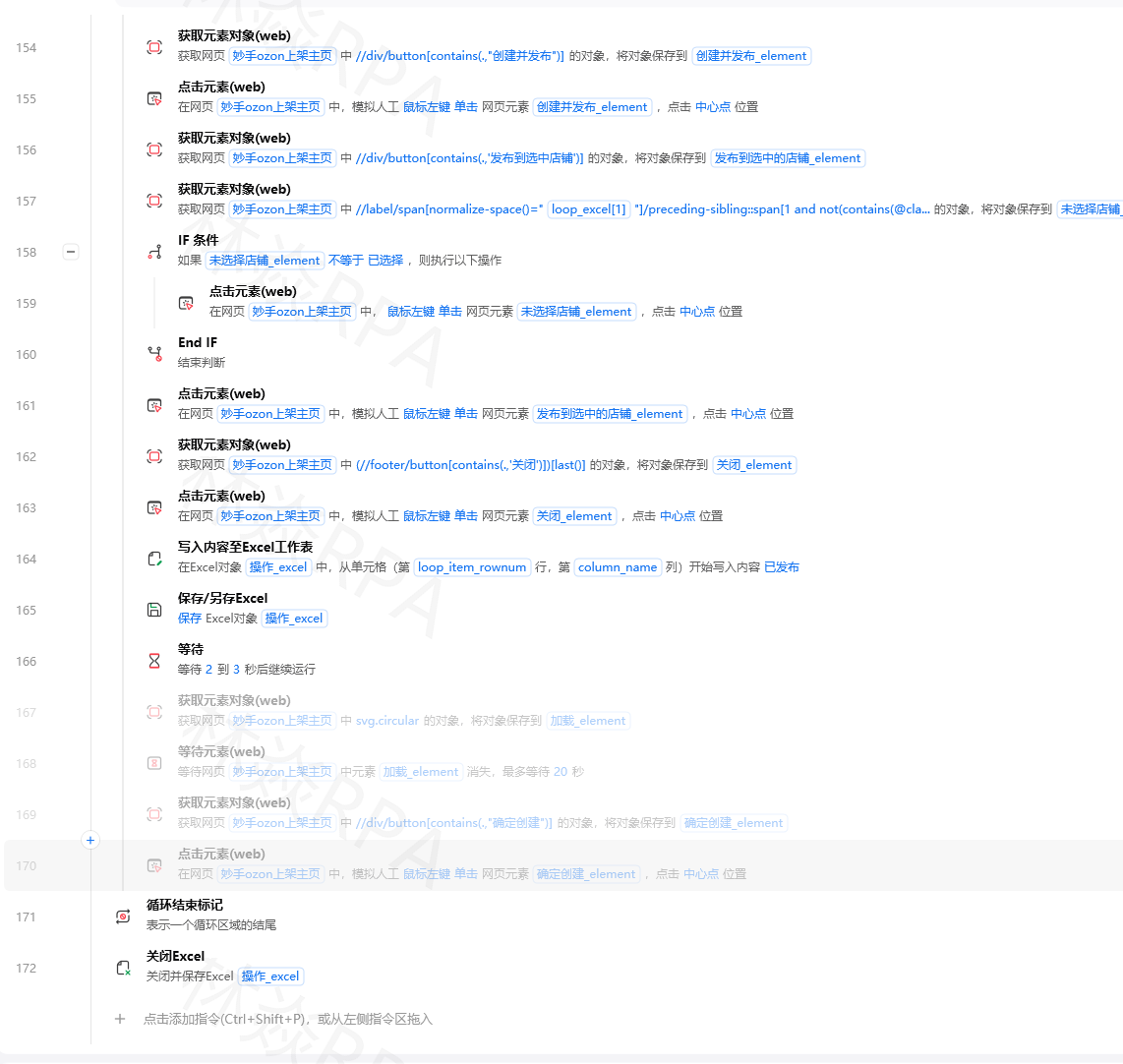web_elementbrowser.find_by_xpath(//*[idsu])CSS选择器和XPath是并列的定位手段。CSS选择器的语法更简洁适合按class、id等属性定位fromxbotimportwebdefmain(args):browserweb.get_active()web_elementbrowser.find_by_css(#su)CSS选择器用#表示id用.表示class。XPath功能更强大能做复杂的层级关系查找CSS选择器写起来更快。日常使用中简单的定位用CSS复杂的层级关系用XPath两者搭配着用最顺手。正则表达式在元素定位中不是直接定位方式但在数据提取时特别有用。比如你从网页上抓到了一段文本价格128.00想提取出数字部分用正则\d\.?\d*就能匹配出来。三、变量与数据类型变量就是存数据的容器。影刀里的变量类型常见的有字符串文本、数字、列表、字典、布尔值True/False。拼多多店群自动化上架方案在影刀里创建变量很简单在变量面板点添加变量设置名称和类型就行。注意一个坑某些对象类型的变量比如Excel对象、网页对象无法在创建时给默认值默认是None。如果你在对这些变量操作之前没有先执行启动Excel或获取已打开的网页对象给它们赋值就会报错AttributeError: NoneType object has no attribute xxxx。这个报错新手几乎都会遇到我当年也栽在这上面。我排查了一下午才发现原因就是变量没初始化。解决办法就是在使用对象变量之前一定要先用对应的指令给它赋上有效的值。四、流程控制让影刀按你的逻辑做事For循环是最常用的。比如你要处理Excel里的100行数据就用For循环遍历每一行。影刀里有For次数循环和For Each循环两种前者按次数循环后者遍历列表中的每一项。While循环适合不确定循环次数的场景。比如翻页采集数据你不知道有多少页就 While 判断下一页按钮是否存在存在就继续不存在就退出。If条件判断不用说太多就是如果满足条件就做A否则做B。关键是条件要写对尤其是判断元素文本内容的时候记得先检查元素是否存在不然对None做判断会直接报错。Try-Catch是很多人忽略的。我第一次做小红书采集器的时候偶尔某条笔记的数据格式不一样程序就崩了后面几十条全丢了。后来加上Try-Catch遇到异常就跳过继续流程才稳定下来。五、网页自动化网页自动化是影刀最常用的场景。核心指令包括打开网页、点击元素、填写输入框、获取元素文本等。等待策略特别重要。网页加载需要时间如果你在页面还没加载完就去操作元素必定报错。影刀提供了wait_appear()和wait_disappear()两个方法fromxbotimportwebdefmain(args):browserweb.get_active()is_appearbrowser.wait_appear(搜索结果,timeout20)这行代码会等待搜索结果这个元素出现最多等20秒。网页操作中每一步关键操作前加上等待能解决80%的稳定性问题。弹窗处理用handle_javascript_dialog()方法可以自动点击确认或取消。翻页是采集类流程的核心操作。常规做法是点击下一页按钮等待新页面加载然后继续处理。如果翻页后网页刷新了之前的相似元素列表就失效了需要改用For次数循环在循环内重新获取元素列表按索引去操作。懒加载页面比如小红书搜索结果往下滚会加载更多需要先滚动页面再采集。影刀提供了scroll_to()方法fromxbotimportwebdefmain(args):browserweb.get_active()browser.scroll_to(locationbottom,behaviorsmooth)iframe内嵌网页的处理也不难但很多人不知道。如果一个网页里嵌了另一个网页iframe你直接捕获iframe里的元素可能捕获不到需要先切换到iframe里。影刀在元素捕获时可以自动处理iframe但在代码模式里需要额外注意。六、数据处理Excel读写是最基本的数据操作。影刀的Excel指令包括启动Excel、读取单元格、写入单元格、获取当前激活的Sheet、循环Excel内容等。一个典型的流程是启动Excel——读取数据——处理数据——写回Excel——关闭Excel。注意操作完一定要关闭Excel不然文件会被锁住其他程序打不开。JSON解析在处理API返回数据时经常用到。影刀的Python环境里直接用json.loads()就行。数据库操作影刀也支持但新手阶段用得不多。如果需要连接数据库影刀提供了相应的指令不过配置连接字符串的时候容易写错报错信息通常是连接超时或者认证失败仔细检查连接参数就行。七、鼠标键盘图像自动化有些软件元素捕获不到比如某些远程桌面、游戏画面这时候就只能用鼠标键盘模拟操作了。影刀提供了点击、双击、右键、拖拽、输入键盘快捷键等指令。图像自动化是通过截图匹配来定位的。先截一张目标区域的图保存为图像元素运行时影刀会在屏幕上找匹配的区域。这种方式不如元素定位精确但对付那些无法元素捕获的软件很管用。我第一次做某个ERP系统的自动化时就遇到了元素捕获不到的情况排查后发现是录屏软件干扰了捕获。关掉录屏软件就好了如果实在关不掉就用图像自动化或者快捷键来操作。八、进阶技能HTTP请求可以让你直接和服务器通信不需要打开浏览器。影刀提供了发送HTTP请求指令支持GET、POST等方法。比如你想调用一个API获取数据直接发HTTP请求比操作网页快得多。Python脚本是影刀的杀手锏。影刀的底层就是Python你可以在流程中直接写Python代码调用任何Python库。需要安装第三方库的话在影刀的Python环境里pip install就行。上面展示的所有代码示例都是影刀支持的Python写法。OCR文字识别用于处理图片中的文字。影刀内置了OCR能力支持通用文字识别、身份证识别、银行卡识别、增值税发票识别等importxbotfromxbotimportprintdefmain(args):ocr_enginexbot.ai.BaiduAI()ocr_imagexbot.ai.XbotImage.from_screen()ocr_resultocr_engine.accurate_basic(ocr_image)forwordinocr_result[words]:print(word[text])这段代码会截取屏幕内容并用高精度OCR识别文字。OCR有免费额度超出后需要充值。ADB手机自动化是影刀的另一个亮点。通过ADB连接安卓手机可以自动操作手机上的App。连接方式有USB和WiFi两种需要在手机上开启开发者模式和USB调试。九、平台实战小红书笔记采集器现在用一个完整案例把前面的知识串起来。我们要做一个小红书笔记采集器功能是打开小红书搜索关键词采集搜索结果中的笔记标题、作者、点赞数保存到Excel。第一步打开小红书网页版并搜索关键词。用打开网页指令打开小红书捕获搜索框元素输入关键词点击搜索按钮。搜索前记得等待页面加载完成。第二步采集当前页的笔记列表。用循环相似元素(web)遍历每条笔记卡片在循环内用获取元素文本提取标题、作者、点赞数。如果有些数据用元素捕获拿不到可以考虑用XPath或CSS选择器精确定位fromxbotimportwebdefmain(args):browserweb.get_active()notesbrowser.find_all(笔记卡片)fornoteinnotes:titlenote.find_by_css(.title).get_text()authornote.find_by_css(.author).get_text()第三步滚动加载更多内容。小红书搜索结果是懒加载的需要先滚动页面再继续采集。第四步将数据写入Excel。启动Excel把采集到的数据逐行写入最后保存并关闭。第五步异常处理。加上Try-Catch某条笔记采集失败就跳过继续不中断整个流程。TEMU店群如何管理运营第二个实战案例是淘宝商品采集。和小红书类似但淘宝页面结构更复杂而且淘宝有反爬机制。采集图片时先捕获图片相似元素组然后用获取元素属性批量获取src属性值。注意src可能不带https前缀需要拼接后才能下载。也可以用JavaScript直接获取完整链接function(element,input){returnelement.src;}淘宝还有限制一次性最多导出10000条订单。处理大批量数据时需要按时间段分批查询每批控制在9000条以内防止超限导致导出失败。十、系统联动飞书通知非常实用。采集完数据后让影刀自动发一条消息到飞书群你就能第一时间知道结果。影刀提供了飞书群通知指令只需要填入机器人的webhook地址就行飞书群通知支持文本、图片、富文本、消息卡片四种格式。文本格式最简单直接发纯文本消息消息卡片格式最灵活可以用飞书的卡片搭建工具设计排版。如果你在飞书机器人的安全设置中勾选了签名校验还需要在影刀里填入对应的密钥。邮件发送也是常见需求影刀提供了发送邮件指令配置SMTP服务器和账号就行。定时任务让你不用手动触发影刀可以按设定的时间自动运行流程。在影刀控制台里设置定时任务指定运行时间和重复规则即可。十一、工程化与规范子流程是影刀里组织代码的基本方式。一个复杂流程不要全堆在主流程里按功能拆分成多个子流程比如登录模块“采集模块”“存储模块”主流程只负责调用子流程。子流程之间可以互相调用也可以有输入参数和输出参数。调试是解决问题最重要的手段。在可能出错的指令前打断点点击行号旁边的空白处出现橙色圆点运行到断点会暂停你可以在下方的调试变量面板查看所有变量的值和类型。断点调试是我每天都要用的功能比猜来猜去效率高十倍。命名规范看似不起眼但变量名和子流程名起得好后面维护起来省很多时间。建议变量名用类型_用途的格式比如str_keyword、list_results、obj_browser。版本管理在影刀控制台里可以操作每次修改前记得保存版本出了问题可以回退。十二、速查表与常见报错最后整理一份常用指令和常见报错的速查表。常见报错及解决方案AttributeError: NoneType object has no attribute xxxx——变量没赋值就使用了检查前面的指令是否正确执行并给变量赋了有效值。Can not convert Array to String——把列表当字符串用了循环Excel内容时循环项是列表需要用索引取出具体值再填入。UIAError: 等待元素超时——元素没出现就操作了增加等待时间或检查元素定位是否正确。网页刷新后元素找不到——网页刷新后之前获取的元素失效改用For次数循环在循环内重新获取元素。元素捕获不到——关闭桌面管理工具和录屏软件或切换到深度模式捕获或改用图像自动化。Excel对象为None——在使用Excel对象前没有执行启动Excel或获取当前激活的Excel指令。飞书通知发送失败——检查webhook地址是否正确如果开了签名校验需要填入密钥。OCR识别额度不足——影刀OCR有免费额度超出后需要到个人中心充值。HTTP请求返回401——接口未授权检查accessKeyId和accessKeySecret是否正确。淘宝数据导出超过10000条——需要按时间段分批导出每批控制在9000条以内。常用指令速查打开网页 / 获取已打开的网页对象捕获新元素 / 捕获相似元素点击元素 / 填写输入框 / 获取元素文本获取元素对象(web)——支持CSS和XPath定位循环相似元素(web) / For次数循环 / While循环启动Excel / 读取单元格 / 写入单元格发送HTTP请求 / HTTP下载飞书群通知 / 发送邮件执行Python脚本OCR文字识别连接手机(ADB)影刀RPA学习主页 home.linyan.cloud 有更多实战案例和进阶教程。写这篇文章的过程中我不断回想起自己刚入门时的那种无力感——到处搜教程踩一个坑卡半天。希望这篇指南能让你少走些弯路。RPA不难难的是没人告诉你那些坑在哪。现在你知道了去试试吧。#影刀RPA #RPA教程 #新手入门作者林焱。
相关新闻
)
【日耕一题】7. 循环右移(2026第17届蓝桥杯C++B组省赛 C 题)

【OpsPilot-07】基础模块的接口契约测试与前后端联调验证

大模型微调灾难性遗忘2026:LoRA+SFT+DPO联合缓解的工程方案
最新新闻
![如何用Gemma-4-26B-A4B-StyleTune提升创作质量?新手必看的AI写作指南 [特殊字符]](http://pic.xiahunao.cn/yaotu/如何用Gemma-4-26B-A4B-StyleTune提升创作质量?新手必看的AI写作指南 [特殊字符])
如何用Gemma-4-26B-A4B-StyleTune提升创作质量?新手必看的AI写作指南 [特殊字符]

10个CatSniffer实用技巧:从基础嗅探到高级攻击的完整教程

Bernini-R-GGUF-ComfyUI安装教程:5分钟快速部署AI视频生成环境

Qwythos-9B函数调用完全手册:构建AI驱动的自动化工具链

解锁Java生态宝藏:从零构建企业级知识图谱的技术架构深度剖析
![Sapiens2-Pose-0.4B vs 其他姿态估计模型:为什么它是最佳选择?[特殊字符]](http://pic.xiahunao.cn/yaotu/Sapiens2-Pose-0.4B vs 其他姿态估计模型:为什么它是最佳选择?[特殊字符])
Sapiens2-Pose-0.4B vs 其他姿态估计模型:为什么它是最佳选择?[特殊字符]
日新闻
)
UVA10082 WERTYU(洛谷-UVA10082)

2026怎么选能支持多流派解盘逻辑的AI辅助解盘工具?资深专家教你看懂底层算力



